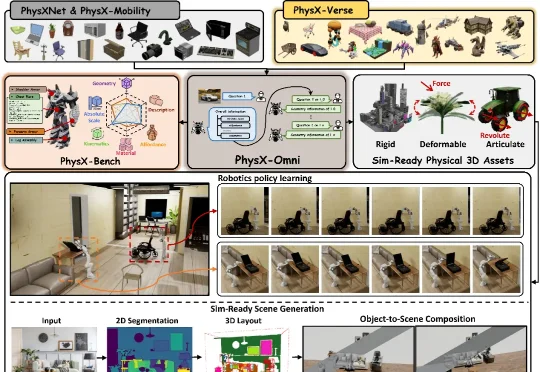
大晓机器人联合南洋理工打通Physical AI全链路!PhysX-Omni补齐物理AI基建
大晓机器人联合南洋理工打通Physical AI全链路!PhysX-Omni补齐物理AI基建该论文第一作者为曹子昂,研究方向主要聚焦于 3D AIGC、Physical AI 与具身智能。论文主要合作者包括来自南洋理工大学的李海天、姚润茂、洪方舟、陈昭熹,以及大晓机器人的刘英豪和潘亮。通讯作者为南洋理工大学刘子纬教授。
来自主题: AI技术研报
8783 点击 2026-06-07 10:55